半年时间市值狂飙近20倍 但每收进1元就要亏掉6.5元 资本为何押注智谱?
杭州网 发布时间:2026-06-23 07:24
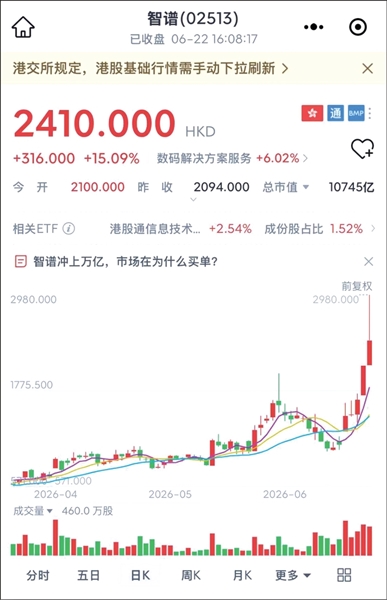
如果你在智谱上市那天买了价值100万元的股票,半年后的今天,账上躺着近2000万元。
昨天,国产大模型龙头智谱(02513.HK)继续大幅上涨,总市值历史性突破1万亿港元。股价最高报2980港元,从1月上市后的最低点116.1港元算起,年内累计涨幅最高达2467%。
截至收盘,智谱市值1.07万亿港元,比肩百度,超越小米、美团、京东,成为仅次于腾讯、阿里、字节跳动的第四大科技主体。
半年上涨近20倍,被马斯克亲自翻牌点评。这家从清华实验室走出来的AI公司,到底凭什么?
一场“翻牌”引发的资本狂欢
时间回到一周前。
6月15日,智谱宣布上线并开源新一代旗舰大模型GLM-5.2。这款模型主攻“长程任务”:让AI不再只做即时问答,而能像人一样连续工作数小时、自主跑完一个完整的大型工程。在全球百万用户参与盲测的Code Arena上,GLM-5.2取得全球可用模型第一;在FrontierSWE编程基准测试中得分74.4,超过OpenAI GPT-5.5,仅落后Anthropic顶级闭源模型Claude Opus4.8约1个百分点。
这一成绩很快在硅谷引发热议,连马斯克都参与了讨论。有人向他询问:“中国大模型何时能达到Fable级别?GLM-5.2无疑缩短了差距。”Fable 5是Anthropic 刚发布的Mythos网络安全模型,也是现阶段编程能力最强的大模型,甚至没有之一。
马斯克回复:“可能在2027年第一季度。”而智谱创始人、清华大学教授唐杰信心满满地表示:“用不了这么久。”一时间,won't take that long(用不了那么久)在AI圈子里刷屏。
这场对话之后,智谱股价继续狂飙。但真正让资本和开发者同时买单的,是GLM-5.2拿得出手的实力和性价比。
作为目前公认的国产最强编程模型,GLM-5.2有多抢手?最近,官方提供了限量的Coding Plan订阅服务,每天只在特定时间开放抢购,社交网站上,一堆程序员说“抢不到”。
杭州一位正在创业的OPC说,从纯文本代码和百万长文档阅读单一场景来说,GLM-5.2基本上和GPT-5.5和Opus4.8持平,“但相比 Claude,GLM-5.2的性价比高太多了”。
从API定价来看,GLM-5.2的成本仅为Claude顶级模型的五分之一到七分之一。也因为这个原因,GLM-5.2成为很多对成本敏感的开发者或OPC的最佳选择。
清华实验室
走出的“Coding特种兵”
智谱的故事始于2019年。他们脱胎于清华大学计算机系知识工程实验室(KEG)。核心团队清一色清华系:清华计算机系教授唐杰担任首席科学家,张鹏本硕博均毕业于清华并出任CEO,刘德兵出任董事长。团队汇聚了唐杰、李涓子、许斌等一批清华顶尖科学家。
从成立到市值突破万亿港元,仅用了约7年。不过真正让智谱跑出来的,是一次关键的战略转向。
2025年7月,智谱发布GLM-4.5后,内部做了一次重大调整,把GLM系列的下一代研发资源集中投到Coding(编程)方向,部分负责“多模态”和“长文本”方向的小组,被悄悄并入Coding团队。用唐杰的话说,这次调整整合了代码、推理、Agent三种能力。智谱开始All in Coding。
Coding是大模型商业化最清晰的场景之一,程序员愿意为生产力工具付费,而且付费意愿强、黏性高。去年9月,智谱推出AI驱动的编码工具订阅计划,每月收费低至20元人民币,大约是Anthropic Claude价格的七分之一,很快吸引了超过15万用户。智谱面向开发者的软件工具及模型业务,年度经常性收入已超1亿元。
从GLM-4.7到GLM-5.1再到GLM-5.2,智谱在Coding能力上的迭代肉眼可见。如果说GLM-4.7实现了对彼时顶级编程模型的对齐,到了GLM-5.2,使用体验感已经和Opus级模型基本没有差别。
7年市值破万亿元,到底有多快?完成同样的成绩,腾讯用了16年,阿里巴巴用了20年(港股主体),美团用时10年。也就是说,智谱用7年走完了这些科技大厂十年甚至几十年才走完的路。
更夸张的一个指标是人均市值。2025年年末,智谱一共有1094名员工,按照现有市值计算,人均对应市值是9.8万港元,老大哥腾讯和阿里的这一数字分别为3400港元和1555港元。
非理性定价背后
市场到底在交易什么?
当智谱市值突破万亿元的时候,很多人翻开财报,看到7.24亿营收、47亿亏损(相当于每收进1元就要亏掉6.5元),第一反应是:这价格是不是太离谱了?
事实上,这个问题的答案藏在一整套关于“中国AI核心资产”的叙事里。
就在GLM-5.2发布前,Anthropic宣布Claude Fable 5对全球客户禁用,其中就包括中国用户。被公认为Claude国内最好“平替”的智谱,则做出了全面开放的表态,采用最宽松的MIT协议开源,不限制商用和地域。发布当天即完成与华为昇腾、平头哥等8个国产算力平台的Day0适配。
很多原本在用Claude的国内开发者转头就涌向了GLM-5.2,而智谱也借此在国产算力适配和自主替代这件事上,拿到了一个身位。
不过这只是拼图的一部分。更大的叙事来自“中国版Anthropic”这个标签。
Anthropic用Claude系列验证了一件事,强模型可以通过API、企业服务和Coding场景形成商业闭环,而Coding恰恰是大模型商业化中最容易被付费验证的方向。
在国内外科技巨头疯狂砸钱的当下,Anthropic的估值成功超越OpenAI,证明当下资本市场愿意用真金白银奖励那些能够提供“稀缺服务”的公司,而不是“用户数最多”的公司。换句话说,ChatGPT可以被其他应用替代,Claude很难。
在国内,承担类似角色或者期待的,而且可以在二级市场交易的标的,只有智谱。
但这并不意味着智谱目前的市值是“合理”的。
简单算一笔账,根据华创证券预计,智谱2026年收入约30亿元、2027年约71亿元,如果以2027年的预测收入计算,万亿市值对应的市销率仍超过140倍。但即便是全球最顶尖的AI公司,市销率也不过20~60倍,比如Anthropic只有18倍,OpenAI为34~65倍。
再来看马斯克和唐杰那场隔空对话,它实际上透露了两层含义。一是在Coding领域,中国大模型显然已经能够上桌,就像去年的DeepSeek一样。二是马斯克的回复也明确指出:“在基准测试上或许是这样,但如果以实际落地实用价值来评判,就算明年一季度追上,也会令人印象非常深刻。”
从基准测试,到实际落地,GLM-5.2还有一段路要走。更何况,它的身后还有DeepSeek、kimi、Qwen等一众对手。
(原标题:半年时间市值狂飙近20倍 但每收进1元就要亏掉6.5元 资本为何押注智谱?)
来源:都市快报 作者:记者 沈积慧 编辑:郑海云
返回
